대부분의 상황에서는 구조적 API를 사용하는 것이 좋다. 그러나 비즈니스가 기술적 문제를 고수준 API를 사용해 모두 처리할 수 있는 것은 아니므로, 스파크의 저수준 API를 사용해야 할 수도 있다.
CHAPTER 12. RDD
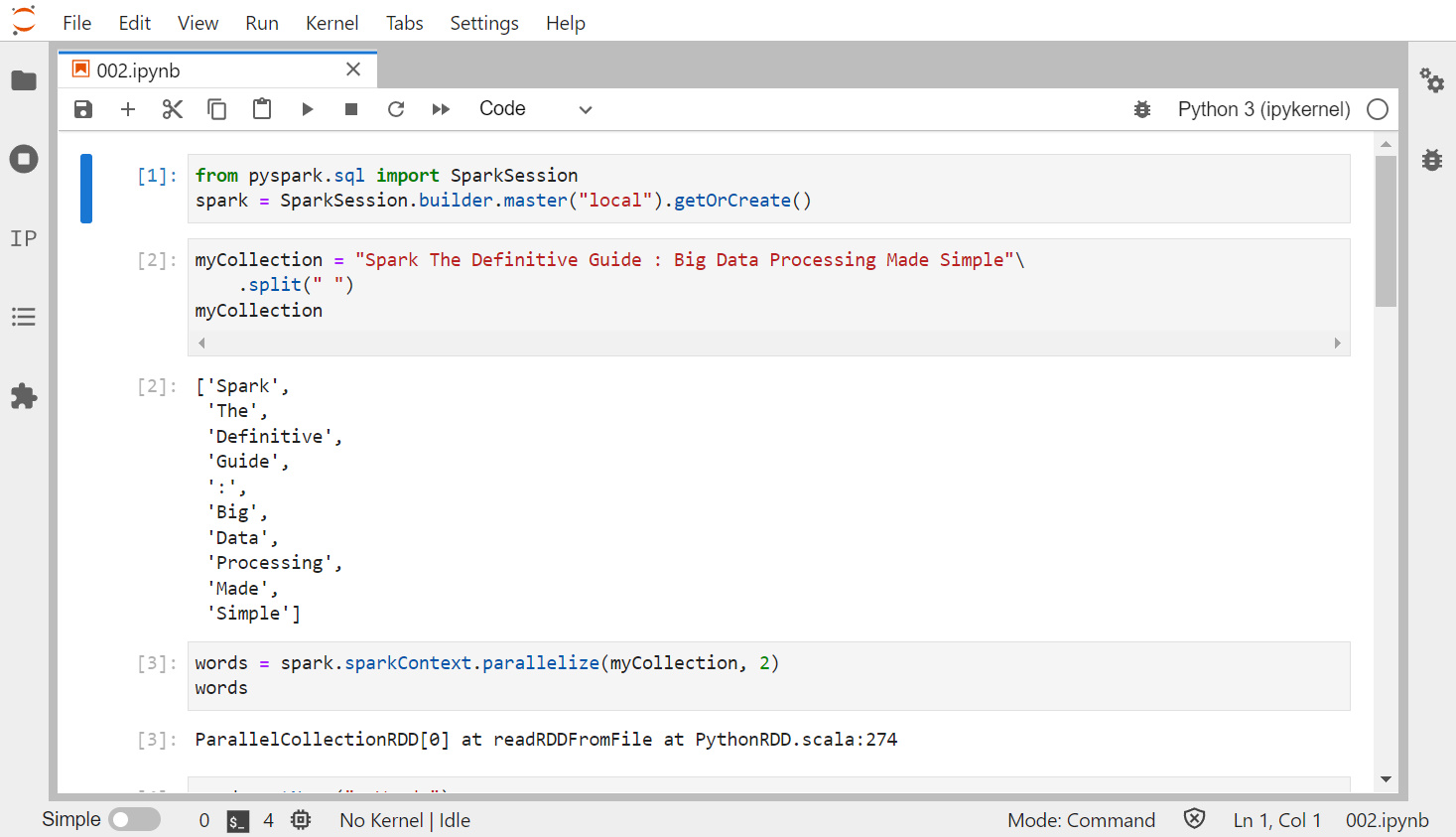
사용자가 실행한 모든 DataFrame이나 Dataset 코드는 RDD로 컴파일된다. RDD는 간단히 말해 불변성을 가지며 병렬로 처리할 수 있는 파티셔닝된 레코드의 모음이다. RDD의 레코드는 자바, 스칼라, 파이썬의 객체일 뿐이다. 또한 구조적 API와는 다르게 레코드의 내부 구조를 스파크에서 파악할 수 없으므로, 최적화를 하려면 훨씬 많은 수작업이 필요하다.
RDD에는 수많은 하위 클래스가 존재하며, DataFrame API에서 최적화된 물리적 실행 계획을 만드는데 대부분 사용된다. 파이썬을 사용해 RDD를 다룰 때는 상당한 성능 저하가 발생할 수 있다.
RDD 다루기 - 트랜스포메이션

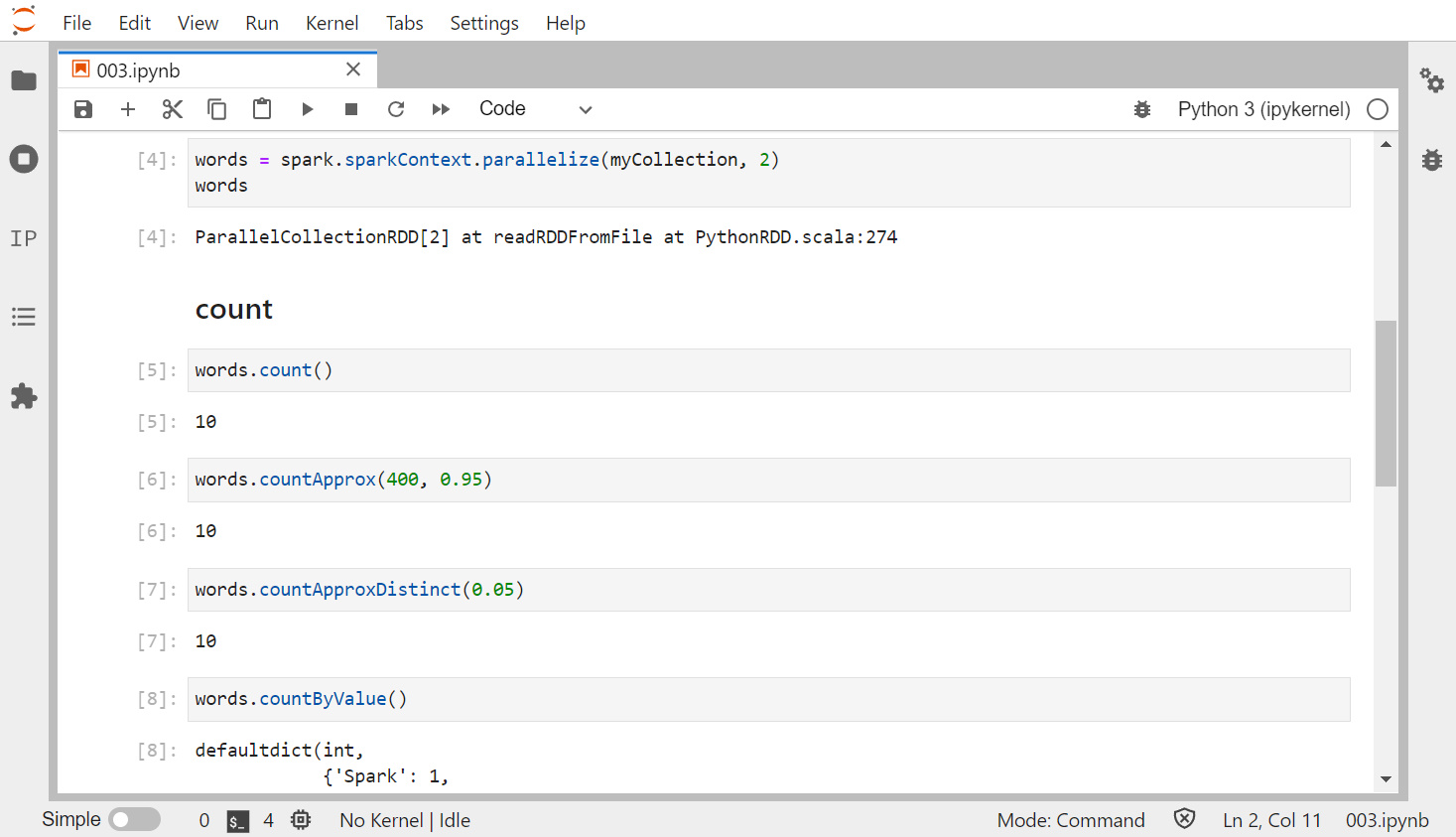
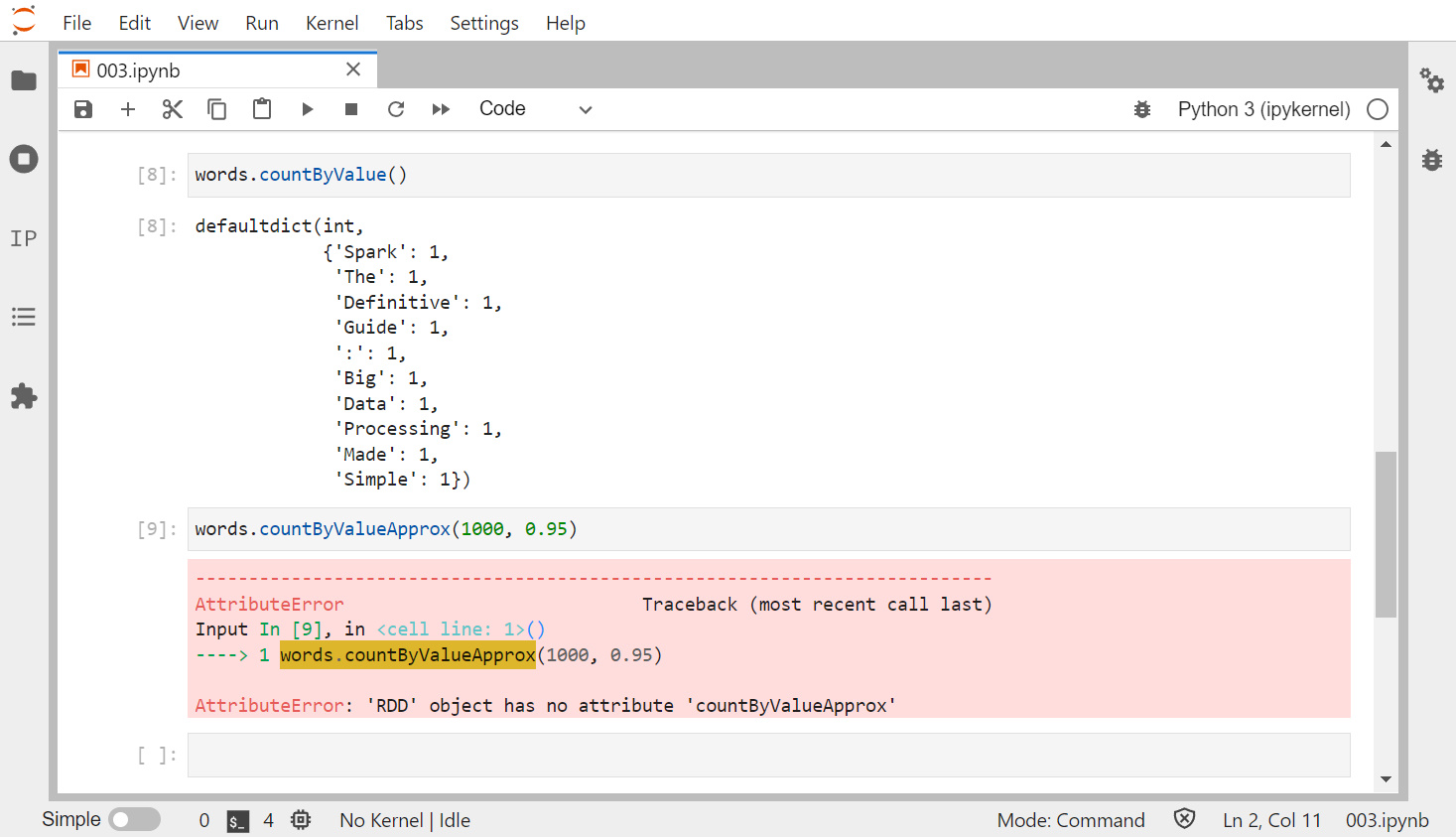
RDD 다루기 - 액션

CHAPTER 14. 분산형 공유 변수
분산형 공유 변수에는 브로드캐스트 변수와 어큐뮬레이터라는 두 개의 타입이 존재한다. 어큐뮬레이터를 사용하면 모든 태스크의 데이터를 공유 결과에 추가할 수 있고, 브로드캐스트 변수를 사용하면 모든 워커 노드에 큰 값을 저장하므로 재전송 없이 ㅁ낳은 스파크 액션에서 재사용할 수 있다.
브로드캐스트 변수
브로드캐스트 변수는 변하지 않는 값(불변성 값)을 클로저 함수의 변수로 캡슐화하지 않고 클러스터에서 효율적으로 공유하는 방법을 제공한다. 모든 캐스크마다 직렬화하지 않고 클러스터의 모든 머신에 캐시하는 불변성 공유 변수이다. 브로드캐스트 변수를 사용한 방식과 클로저에 담아 전달하는 방식의 유일한 차이점은 브로드캐스트 변수를 사용하는 것이 훨씬 더 효율적이라는 것이다. 아주 작은 데이터를 작은 클러스터에서 돌린다면 크게 차이가 나지 않을 수 있지만, 훨씬 큰 크기의 데이터를 사용하는 경우라면 전체 태스크에서 데이터를 직렬화하는 데 발생하는 부하가 매우 커질 수 있다.
어큐뮬레이터
어큐뮬레이터는 트랜스포메이션 내부의 다양한 값을 갱시하는 데 사용한다. 내고장성을 보장하면서 효율적인 방식으로 드라이버에 값을 전달할 수 있다. 어큐뮬레이터의 값은 액션을 처리하는 과정에서만 갱신되고 스파크는 각 태스크에서 어큐뮬레이터를 한 번 만 갱신하도록 제어한다.
'Data Engineering > Spark' 카테고리의 다른 글
| [스파크 완벽 가이드] Part 2. 구조적 API: DataFrame, SQL, Dataset (0) | 2022.04.10 |
|---|---|
| [스파크 완벽 가이드] Part 1. 빅데이터와 스파크 간단히 살펴보기 (0) | 2022.04.10 |