CHAPTER 1. 아파치 스파크란?
스파크는 통합 컴퓨팅 엔진이며, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합
스파크는 네 가지 언어(파이썬, 자바, 스칼라, R)을 지원하며
SQL뿐만 아니라 스트리밍, 머신러닝에 이르기까지 넓은 범위의 라이브러리를 제공

스파크는 저장소 시스템의 데이터를 연산하는 역할만 수행할 뿐 영구 저장소 역할은 수행하지 않음
스파크의 등장 배경
하드웨어의 성능 향상은 2005년경에 멈췄음 → 성능 향상을 위해 병렬 처리가 필요함
결과적으로 데이터 수집 비용은 극히 저렴해졌지만, 데이터는 클러스터에서 처리해야 할 만큼 거대해짐
기존 데이터 처리 애플리케이션의 전통적인 프로그래밍 모델이 한계점이 도래 → 스파크 탄생
스파크 실행하기
jupyter에서 제공하는 공식 docker 이미지를 사용하여 jupyterlab을 엽니다. (spark도 포함되어 있습니다.)
$ git clone https://github.com/pfldy2850/spark-the-definitive-guide.git
$ cd spark-the-definitive-guide
$ docker build . --tag stdg-spark:latest
$ docker run -d --rm ^
-p 8888:8888 -p 4040:4040 ^
-v D:\Dev\spark-the-definitive-guide\jupyterlab:/home/jovyan ^
--name stdg-spark ^
stdg-spark:latest ^
start-notebook.sh --NotebookApp.password='argon2:$argon2id$v=19$m=10240,t=10,p=8$3tOM7HJK1FJkWdNMUEg8AA$RiUIo1/+5d8WgFDyRKZACJX8Gne6ASVINIM175e0lZs'
위 명령어로 컨테이너를 실행시키면,
http://localhost:8888 에 비밀번호가 stdg1234인 Jupyterlab이 실행됩니다.

위와 같이 로컬 스파크 세션을 만들고 샘플 코드를 작동시켜봅니다.
스파크 세션이 만들어지고 job이 실행되었다면,
http://localhost:4040/jobs/ 에 스파크UI가 표시됩니다.

CHAPTER 2. 스파크 간단히 살펴보기
종합 예제
그럼 예제 코드를 한번 실행시켜 봅시다.
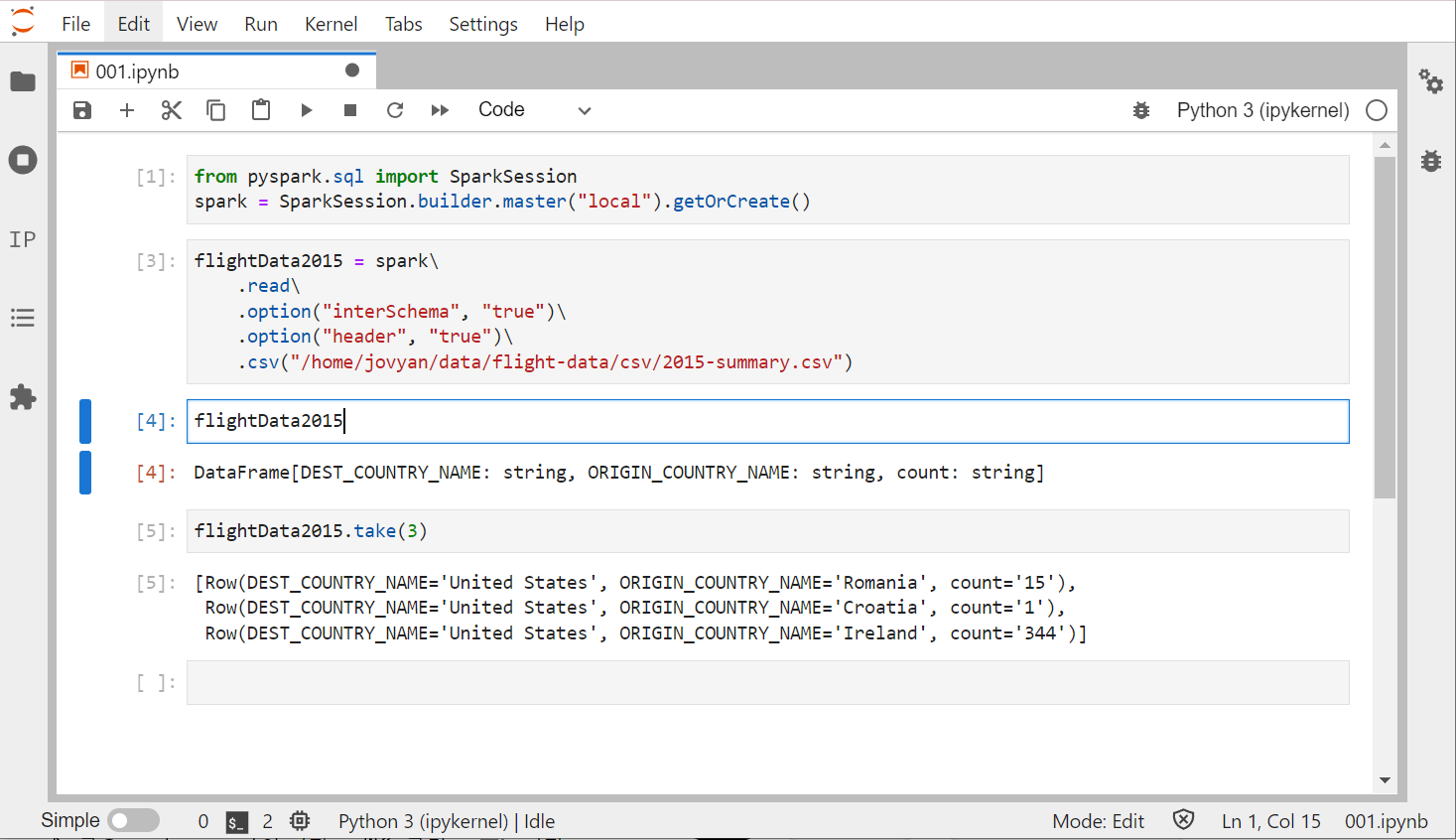
파이썬에서 사용하는 DataFrame은 불특정 다수의 로우와 컬럼을 가집니다.
로우의 수를 알 수 없는 이유는 데이터를 읽는 과정이 지연 연산 형태의 트랜스포메이션이기 때문입니다.
DataFrame의 take 액션을 호출하면 데이터를 읽어옵니다.

explain 메소드는 DataFrame의 계보나 스파크의 쿼리 실행 계획을 확인할 수 있습니다.

DataFrame과 SQL
스파크는 언어에 상관없이 같은 방식으로 트랜스포메이션을 실행할 수 있습니다.
사용자가 SQL이나 DataFrame으로 비즈니스 로직을 표현하면 스파크에서 실제 코드를 실행하기 전에 기본 실행 계획으로 컴파일합니다.
스파크 SQL을 사용하면 모든 DataFrame을 테이블이나 뷰(임시 테이블)로 등록한 후 SQL 쿼리를 사용할 수 있습니다.
SQL 쿼리를 DataFrame 코드와 같은 실행 계획으로 컴파일하므로 둘 사이 성능 차이는 없습니다.


CHAPTER 3. 스파크 기능 둘러보기
Dataset: 타입 안정성을 제공하는 구조적 API
Dataset은 자바와 스칼라의 정적 데이터 타입에 맞는 코드, 즉 정적 타입 코드를 지원하기 위해 고안된 스파크의 구조적 API입니다. Dataset은 타입 안정성을 지원하며 동적 타입 언어인 파이썬과 R에서는 사용할 수 없습니다. 다수의 소프트웨어 엔지니어가 잘 정의된 인터페이스로 상호작용하는 대규모 애플리케이션을 개발하는 데 특히 유용합니다. 스파크는 처리를 마치고 결과를 DataFrame으로 자동 변환해 반환합니다. 또 다른 장점은 collect 메서드나 take 메서드를 호출하면 DataFrame을 구성하는 Row 타입의 객체가 아닌 Dataset에 매개변수로 지정한 타입의 객체를 반환합니다.
구조적 스트리밍
스파크 2.2 버전에서 안정화된 스트림 처리용 고수준 API입니다.
구조적 API로 개발된 배치 모드의 연산을 스트리밍 방식으로 실행할 수 있으며, 지연 시간을 줄이고 증분 처리할 수 있습니다. 구조적 스트리밍은 배치 처리용 코드를 일부 수정하여 스트리밍 처리를 수행하고 값을 빠르게 얻을 수 있다는 장점이 있습니다. 모든 작업은 데이터를 증분 처리하면서 수행됩니다.





스트리밍을 하고 있기 때문에, SQL 질의할 때마다 데이터가 다른 것을 확인할 수 있다.
머신러닝과 고급 분석
스파크는 내장된 머신러닝 알고리즘 라이브러리인 MLlib을 사용해 대규모 머신러닝을 수행할 수 있다. MLlib을 사용하면 대용량 데이터를 대상으로 전처리, 멍잉(munging), 모델 학습 및 예측을 할 수 있다.또한 구조적 스트리밍에서 예측하고자 할 때도 MLlib에서 학습시킨 다양한 예측 모델을 사용할 수 있다.
'Data Engineering > Spark' 카테고리의 다른 글
| [스파크 완벽 가이드] Part 3. 저수준 API (1) | 2022.04.11 |
|---|---|
| [스파크 완벽 가이드] Part 2. 구조적 API: DataFrame, SQL, Dataset (0) | 2022.04.10 |