검색 시스템은 방대한 양의 데이터를 처리하여 사용자에게 적절한 정보를 제공하는 데 중점을 둡니다. 하지만 모든 데이터가 적절히 검색 가능한 형태로 저장되어 있지 않을 때, 검색 품질이 저하될 수 있습니다. 이를 해결하기 위한 핵심 기술 중 하나가 바로 Document Splitting입니다. 이 글에서는 Document Splitting의 개념, 필요성, 구현 사례를 다룹니다.
Document Splitting이란?
Document Splitting은 큰 문서를 더 작은 단위로 나누는 프로세스를 의미합니다. 이 단위는 문장(Sentence), 문단(Paragraph), 또는 사용자가 정의한 특정 논리적 단위(예: 섹션, 챕터 등)일 수 있습니다.
예를 들어, 10페이지에 걸쳐 있는 PDF 파일을 통째로 처리하는 대신, 페이지별 또는 문단별로 나누어 저장 및 검색할 수 있습니다. 이렇게 하면 검색 시스템이 더 효율적으로 작동하고, 검색 결과의 정확도를 높일 수 있습니다.
왜 Document Splitting이 필요한가요?
1. 효율적인 검색 결과 제공
사용자가 특정 질문을 검색할 때, 방대한 문서 전체를 결과로 반환하면 유용성이 떨어질 수 있습니다.
작은 단위로 나뉜 데이터를 처리하면, 더 구체적이고 관련성 높은 결과를 제공할 수 있습니다.
2. 검색 속도 향상
작은 단위로 나뉜 데이터는 검색 엔진이 더 빠르게 처리할 수 있습니다. 검색 쿼리가 단위 데이터에 적용되기 때문입니다.
3. 텍스트 임베딩의 효과 극대화
AI 기반 검색 시스템에서 자주 사용하는 텍스트 임베딩 기법은 입력 데이터의 크기에 민감합니다. 문서가 작게 분리될수록 임베딩의 품질과 관련성 점수가 향상됩니다.
4. 장문의 문서 처리 문제 해결
검색 엔진이 한 번에 처리할 수 있는 데이터 크기에는 제한이 있습니다. 이를 초과하는 문서는 일부가 잘리거나 처리가 실패할 수 있습니다. Splitting을 통해 이러한 문제를 예방할 수 있습니다.
Document Splitting 구현 사례
Document Splitting은 데이터의 특성과 목적에 따라 다양한 방법으로 구현할 수 있습니다. 아래는 일반적인 접근 방식입니다.
1. 문자열 분리
문서 내용을 특정 기준(예: 문장, 문단, 페이지)으로 나눕니다.
Python을 사용한 간단한 구현 예제:
from nltk.tokenize import sent_tokenize
# 큰 문서 예제
large_document = """검색 시스템은 데이터를 처리하여 정보를 제공합니다. Document Splitting은 이를 향상시킬 수 있는 방법입니다."""
# 문장을 기준으로 문서 분리
split_sentences = sent_tokenize(large_document)
print(split_sentences)['검색 시스템은 데이터를 처리하여 정보를 제공합니다.', 'Document Splitting은 이를 향상시킬 수 있는 방법입니다.']
2. 구조 기반 분리
문서에 제목, 섹션 등의 계층적 구조가 있는 경우 이를 기반으로 분리합니다. 예를 들어 HTML, Markdown, PDF 같은 형식에서는 특정 태그나 스타일을 기준으로 나눌 수 있습니다.
from bs4 import BeautifulSoup
# HTML 문서 예제
html_doc = """
<h1>제목</h1>
<p>이 문단은 첫 번째 섹션입니다.</p>
<p>이 문단은 두 번째 섹션입니다.</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
paragraphs = [p.text for p in soup.find_all('p')]
print(paragraphs)['이 문단은 첫 번째 섹션입니다.', '이 문단은 두 번째 섹션입니다.']
3. Semantic Meaning 기반 분리
다른 방법들과 달리, Semantic 기반 분리는 텍스트의 내용을 실제로 고려합니다. 문서나 텍스트 구조를 의미의 대리자로 사용하는 대신, 텍스트의 의미를 직접 분석합니다.
구현 방식은 다양하지만, 개념적으로 텍스트 의미가 크게 변하는 지점을 기준으로 분리합니다.
예를 들어, 슬라이딩 윈도우(sliding window) 방식을 사용하여 임베딩을 생성하고, 임베딩 간의 차이를 비교해 의미 변화가 큰 지점을 찾을 수 있습니다.
from sentence_transformers import SentenceTransformer
import numpy as np
# 텍스트 예제
document = [
"검색 시스템은 데이터를 처리하여 정보를 제공합니다.",
"Document Splitting은 이를 향상시킬 수 있는 방법입니다.",
"AI 기반 검색 엔진은 매우 효과적입니다."
]
# 임베딩 모델 초기화
model = SentenceTransformer('all-MiniLM-L6-v2')
# 슬라이딩 윈도우 방식으로 임베딩 생성
embeddings = [model.encode(sentence) for sentence in document]
# 임베딩 간 유사도 계산
for i in range(len(embeddings) - 1):
similarity = np.dot(embeddings[i], embeddings[i+1]) / (np.linalg.norm(embeddings[i]) * np.linalg.norm(embeddings[i+1]))
print(f"문장 {i}과 문장 {i+1}의 유사도: {similarity:.2f}")
임베딩 간의 유사도가 낮은 지점에서 분리하면, 더 의미적으로 일관된 섹션을 생성할 수 있습니다. 이 방법은 검색, 요약과 같은 후속 작업의 품질을 향상시킬 가능성이 높습니다.
LangChain 예제
How to split text based on semantic similarity | 🦜️🔗 LangChain
Taken from Greg Kamradt's wonderful notebook:
python.langchain.com
# Load Example Data
# This is a long document we can split up.
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
# Create Text Splitter
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
text_splitter = SemanticChunker(OpenAIEmbeddings())
# Split Text
docs = text_splitter.create_documents([state_of_the_union])
print(docs[0].page_content)Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. Last year COVID-19 kept us apart. This year we are finally together again. Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. With a duty to one another to the American people to the Constitution. And with an unwavering resolve that freedom will always triumph over tyranny. Six days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. He thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. He met the Ukrainian people. From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. Groups of citizens blocking tanks with their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland. In this struggle as President Zelenskyy said in his speech to the European Parliament “Light will win over darkness.” The Ukrainian Ambassador to the United States is here tonight. Let each of us here tonight in this Chamber send an unmistakable signal to Ukraine and to the world. Please rise if you are able and show that, Yes, we the United States of America stand with the Ukrainian people. Throughout our history we’ve learned this lesson when dictators do not pay a price for their aggression they cause more chaos. They keep moving.
아래 글을 다양한 breakpoints에 대해 splitting
ANN(Approximate Nearest Neighbor) 알고리즘의 이해 #2 Flat, LSH, IVF, HNSW + SQ, PQ, RPQ
벡터 검색과 ANN(Approximate Nearest Neighbor) 알고리즘은 대규모 데이터셋에서 유사한 항목을 빠르게 찾는 데 필수적인 기술입니다. 본 글에서는 다양한 벡터 검색 인덱스에 대해 소개
dytis.tistory.com
embedding은 BAAI/bge-m3 사용
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-m3"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
hf = HuggingFaceBgeEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
Percentile
text_splitter = SemanticChunker(hf, breakpoint_threshold_type="percentile")
text_splitter.create_documents([orgin_doc])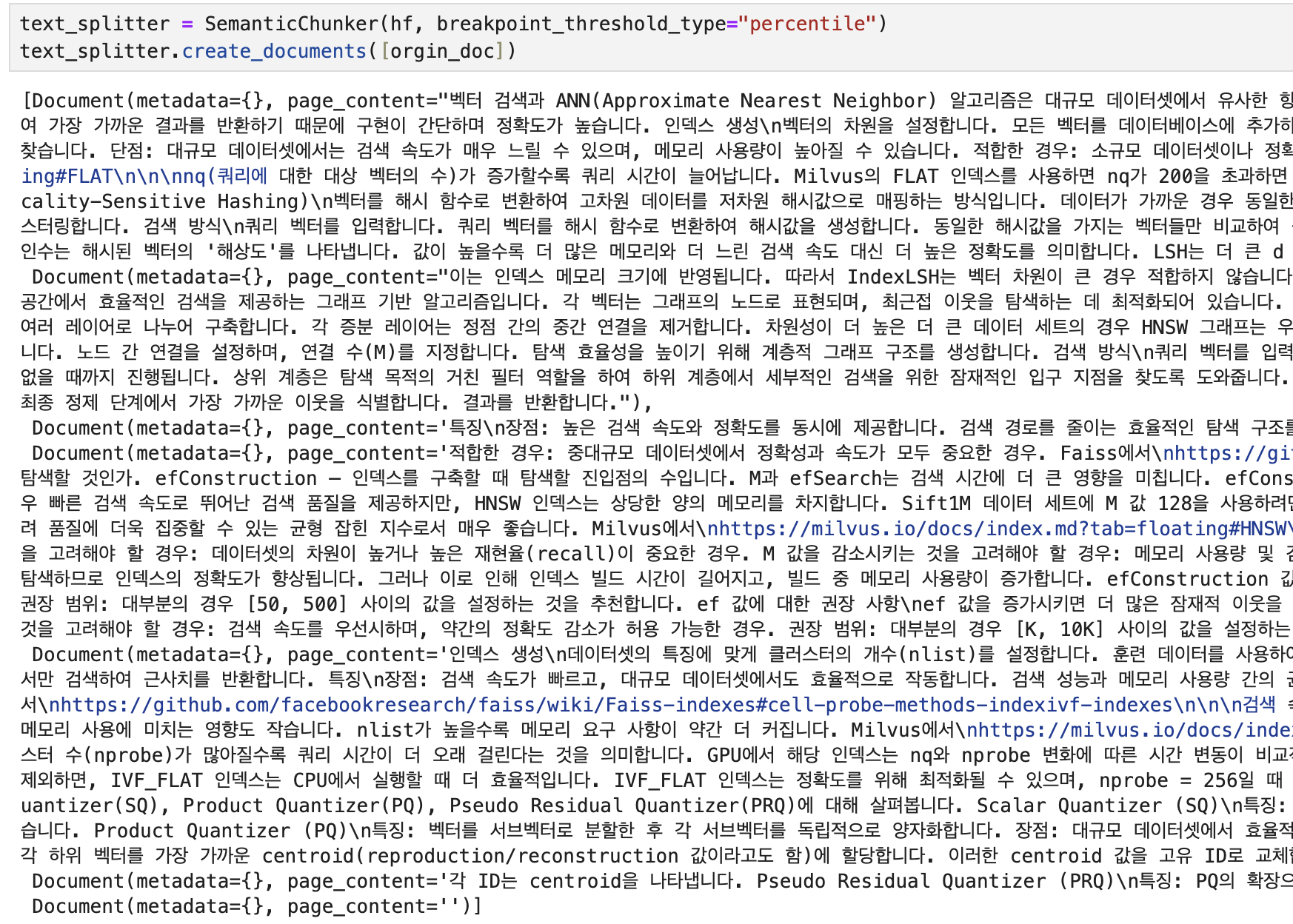
Standard Deviation
text_splitter = SemanticChunker(hf, breakpoint_threshold_type="standard_deviation")
text_splitter.create_documents([orgin_doc])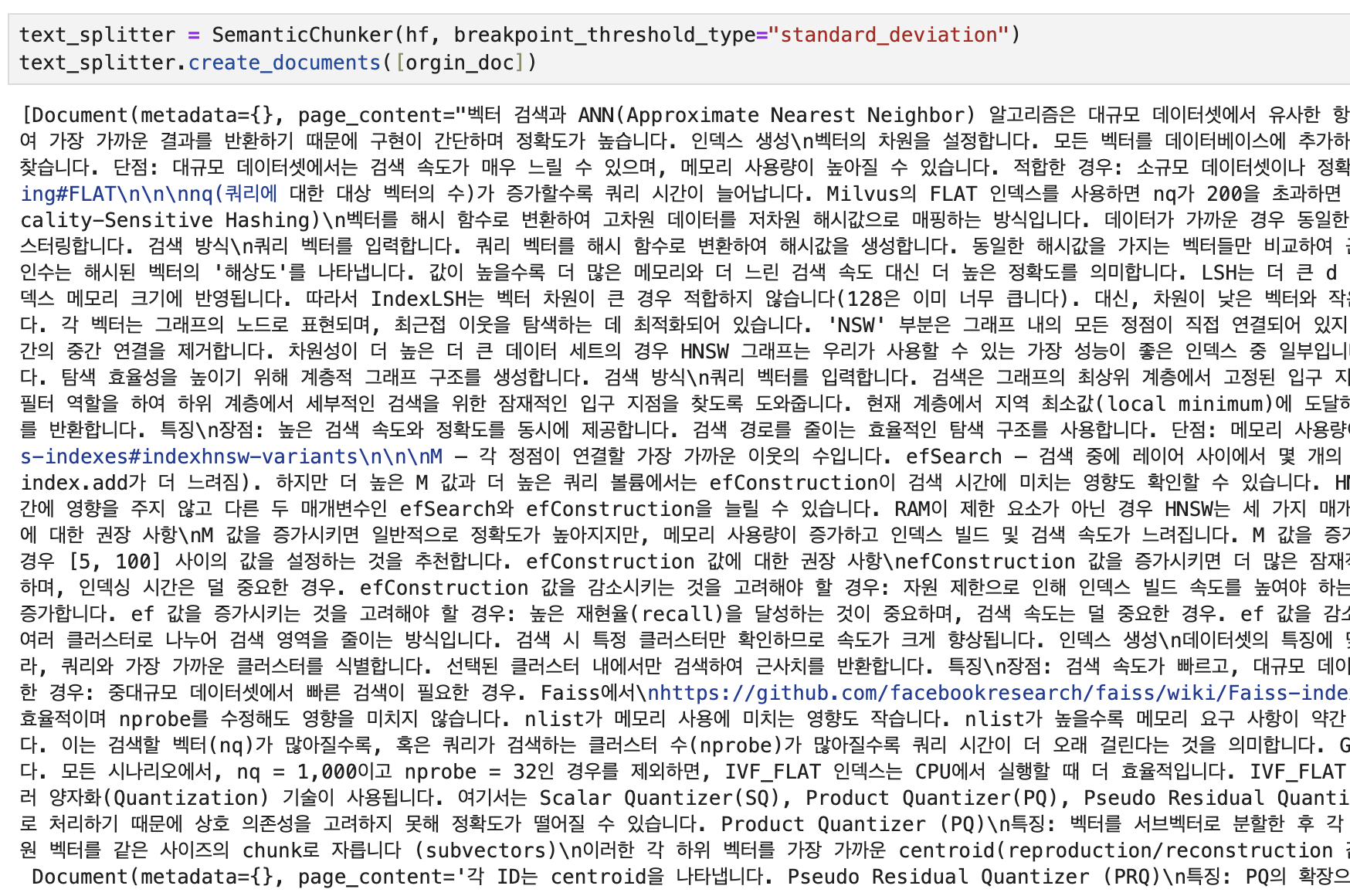
Interquartile
text_splitter = SemanticChunker(hf, breakpoint_threshold_type="interquartile")
text_splitter.create_documents([orgin_doc])
Gradient
text_splitter = SemanticChunker(hf, breakpoint_threshold_type="gradient")
text_splitter.create_documents([orgin_doc])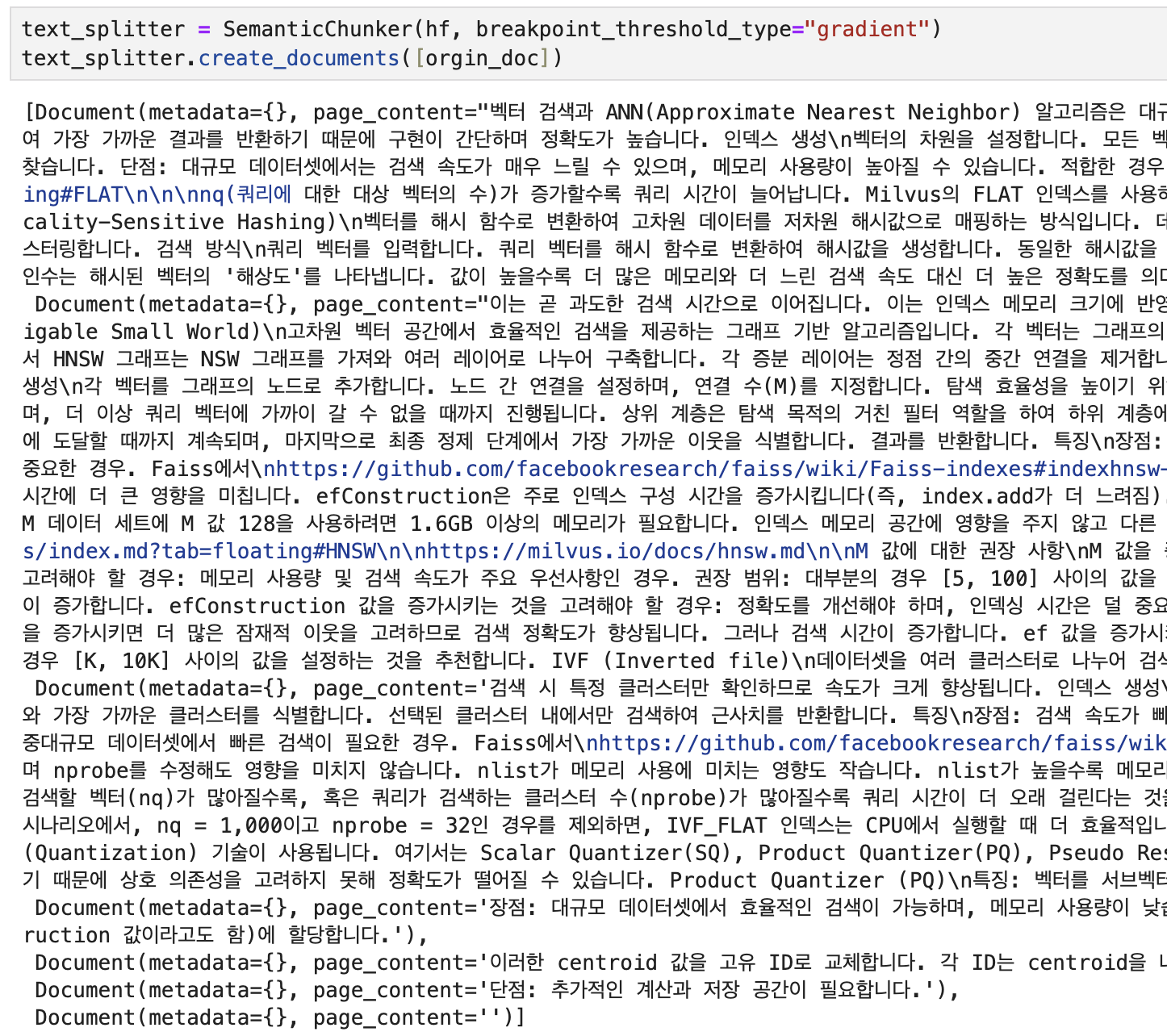
'AI > 검색 시스템' 카테고리의 다른 글
| Milvus #1 - 아키텍처 (0) | 2025.04.22 |
|---|---|
| ANN(Approximate Nearest Neighbor) 알고리즘의 이해 #3 DiskANN (0) | 2025.01.26 |
| ANN(Approximate Nearest Neighbor) 알고리즘의 이해 #2 Flat, LSH, IVF, HNSW + SQ, PQ, RPQ (0) | 2025.01.26 |
| ANN(Approximate Nearest Neighbor) 알고리즘의 이해 #1 (0) | 2025.01.26 |
| Retrieval 시스템을 위한 MTEB 벤치마크 (2) | 2025.01.03 |